from langchain_community.document_loaders import WebBaseLoader from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain.chains.combine_documents import create_stuff_documents_chain
# 直接为docs生成总结 result = chain.invoke({"context": docs}) print(result) # 流式输出 # for token in chain.stream({"context": docs}): # print(token, end="|")
# The README.md file for the "awesome-python-cn" repository, maintained by the "开源前哨" and "Python开发者" WeChat public account teams, provides a comprehensive list of Python resources in Chinese. It includes various tools and libraries categorized under themes such as environment management, package management, web frameworks, data visualization, machine learning, and more. Each category lists specific libraries and tools along with brief descriptions, covering a wide range of functionalities from handling HTTP requests to performing scientific calculations and creating graphical user interfaces. The project aims to facilitate the development of Python applications by providing access to valuable resources and community contributions.
1. 环境准备和依赖导入
当token不足够容纳文档时,我们需要进行文档分割和合并摘要。首先,让我们导入所需的库和组件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from langchain_community.document_loaders import WebBaseLoader from langchain_openai import ChatOpenAI from langchain.chains.llm import LLMChain from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_text_splitters import CharacterTextSplitter import asyncio import operator from typing import Annotated, List, Literal, TypedDict from langchain.chains.combine_documents.reduce import ( acollapse_docs, split_list_of_docs, ) from langchain_core.documents import Document from langgraph.constants import Send from langgraph.graph import END, START, StateGraph
# 单文档摘要链 map_prompt = ChatPromptTemplate.from_messages( [("system", "Write a concise summary of the following:\\n\\n{context}")] ) map_chain = map_prompt | llm | StrOutputParser()
# 摘要合并链 reduce_template = """ The following is a set of summaries: {docs} Take these and distill it into a final, consolidated summary of the main themes. """ reduce_prompt = ChatPromptTemplate([("human", reduce_template)]) reduce_chain = reduce_prompt | llm | StrOutputParser()
Created a chunk of size 1254, which is longer than the specified 1000 ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['generate_summary'] ['collect_summaries'] ['collapse_summaries'] ['collapse_summaries'] ['collapse_summaries'] ['collapse_summaries'] ['collapse_summaries'] ['collapse_summaries'] ['generate_final_summary'] {'generate_final_summary': {'final_summary': '### Consolidated Summary of Python Resources and Libraries\n\nThe Python ecosystem offers a diverse range of resources, libraries, and frameworks that cater to various programming needs, highlighting its versatility and extensive functionality:\n\n1. **Web Development**: Frameworks like Django and Flask, along with libraries such as BeautifulSoup, support web applications and web scraping.\n\n2. **Data Handling and Processing**: Libraries like pandas, NumPy, and Dask facilitate efficient data manipulation and processing, while tools like PySpark and Ray enhance data analysis capabilities. \n\n3. **Scientific Computing and Machine Learning**: Essential libraries for data analysis include SciPy and visualization tools such as matplotlib and Plotly, complemented by machine learning frameworks like TensorFlow and PyTorch.\n\n4. **Asynchronous Programming and Task Automation**: Libraries such as asyncio, Celery, and APScheduler improve application responsiveness and workflow management.\n\n5. **Development Tools and Quality Assurance**: Tools like Jupyter Notebook, Flake8, and pytest focus on improving code quality, testing, and maintenance.\n\n6. **Environment and Package Management**: Tools like pip and conda streamline the management of packages and development environments.\n\n7. **Security and Data Integrity**: Libraries like cryptography ensure secure data handling and management.\n\n8. **Cloud Integration and DevOps**: Tools such as boto3 and Ansible facilitate integration with cloud services and infrastructure management.\n\n9. **Gaming and GUI Development**: Frameworks like Pygame and libraries like Tkinter offer options for game and graphical user interface development.\n\n10. **Networking, API Development, and Specialized Applications**: Libraries like Mininet and scapy support networking tasks, while tools like Graphene assist with API development, catering to specialized areas such as robotics and finance.\n\n11. **Documentation and Community Engagement**: Tools like Sphinx and curated tutorials foster community contributions and project documentation.\n\nThis summary underscores the comprehensive and open-source nature of the Python toolkit, emphasizing its broad applicability across various domains and industries.'}}
from langchain_community.document_loaders import WebBaseLoader from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain.chains.llm import LLMChain from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_text_splitters import CharacterTextSplitter import asyncio import operator from typing import Annotated, List, Literal, TypedDict
from langchain.chains.combine_documents.reduce import ( acollapse_docs, split_list_of_docs, ) from langchain_core.documents import Document from langgraph.constants import Send from langgraph.graph import END, START, StateGraph
#2 长文本总结 # 生成一段摘要的链 map_prompt = ChatPromptTemplate.from_messages( [("system", "Write a concise summary of the following:\\n\\n{context}")] )
map_chain = map_prompt | llm | StrOutputParser()
# 将多个摘要合并的链 reduce_template = """ The following is a set of summaries: {docs} Take these and distill it into a final, consolidated summary of the main themes. """
# 计算输入文档列表的总token deflength_function(documents: List[Document]) -> int: """Get number of tokens for input contents.""" returnsum(llm.get_num_tokens(doc.page_content) for doc in documents)
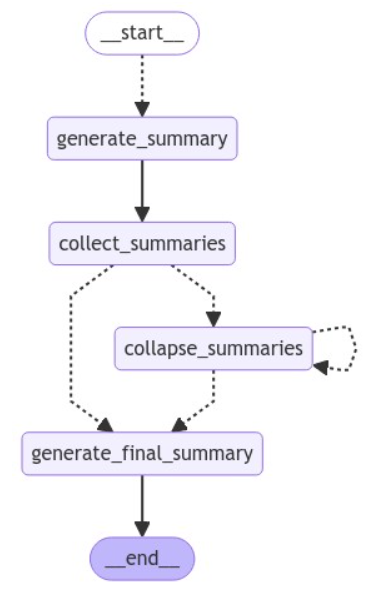
app = graph.compile() # from IPython.display import Image # Image(app.get_graph().draw_mermaid_png())
asyncdefmain(): asyncfor step in app.astream( {"contents": [doc.page_content for doc in split_docs]}, {"recursion_limit": 10}, ): print(list(step.keys()))