8.使用langgraph实现带条件分支的RAG问答系统
在这篇教程中,我们将深入探讨如何使用 langgraph 框架构建一个带有条件分支的智能问答系统。我们将通过逐步分析代码,了解每个部分的功能,并解释其背后的原理。最终的目标是使您能够创建一个能够从网页文档中提取信息并选择是否使用提取信息来回答用户问题的 AI 助手。
1. 引入所需的库
首先,我们需要导入一些必要的库和模块。这些库将帮助我们处理网页数据、进行文本分割、嵌入和检索等操作。
1 | import bs4 |
2. 初始化语言模型
接下来,我们将初始化一个聊天模型,这里我们使用的是 OpenAI 的 GPT-4o 模型。temperature=0:设置温度为 0,意味着模型将生成更确定的答案,而不是随机的。
1 | # 大模型 |
3. 加载网页文档
我们使用 WebBaseLoader 从指定的 URL 加载文档,并仅解析列表项(li 标签)。
1 | # 文档加载 |
4. 文档分割
加载文档后,我们需要将其分割成更小的部分,以便进行处理和嵌入。
1 | # 文档分割 |
5. 文档嵌入存储
接下来,我们将为分割后的文档生成嵌入,并将其存储在内存向量存储中。
1 | # 文档嵌入存储 |
6. 创建检索工具
我们将创建一个工具,用于根据用户的查询检索相似文档。
1 |
|
retrieve函数:接收查询并返回与之相似的文档。similarity_search:在向量存储中查找与查询最相似的文档。
7. 处理用户查询
我们定义一个函数来处理用户的查询并生成响应。
1 | # 生成可能包含工具调用的 AIMessage |
query_or_respond:语言模型通过绑定检索工具,从而可以根据需要决定是否使用检索工具,response可能包含两种类型的内容:普通的文本响应或工具调用请求,这是后续条件分支判断走哪条路的依据。
8. 生成最终响应
接下来,我们将生成最终的答案。
1 | # 使用检索到的内容生成回复 |
generate函数:该函数的主要任务是从检索到的文档中生成答案。它首先获取最近的工具消息,然后将这些消息格式化为适合传递给语言模型的提示。- 获取工具消息:通过逆序遍历
state["messages"],我们可以找到最近的工具消息,这些消息包含了与用户查询相关的上下文信息。然后将获取到的工具消息反转,以确保它们按照正确的顺序进行处理。 - 连接文档内容:通过
docs_content,将所有工具消息的内容连接起来,形成一个完整的上下文,以便语言模型使用。 - 构建系统消息:
system_message_content指示模型其角色和回答问题的方式,强调回答的简洁性和准确性,并加入检索到的文档内容。 - 提取对话消息:
conversation_messages从消息状态中提取人类和系统消息,以便在生成最终响应时使用。 - 生成提示:最终的提示
prompt结合了系统消息和对话消息,作为输入传递给语言模型。 - 生成响应:调用语言模型生成的响应,最终返回给调用者。
- 获取工具消息:通过逆序遍历
9. 构建状态图
我们使用 StateGraph 来管理整个流程的状态。
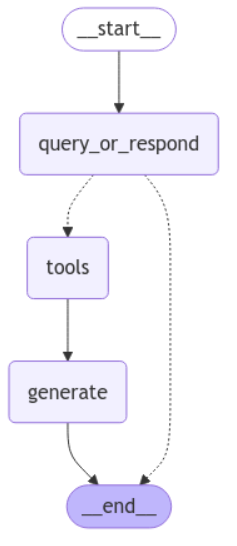
1 | # 图定义 |
StateGraph:这是一个用于定义和管理状态流转的结构。它允许我们将不同的处理步骤组织成一个图形结构,以便在处理用户输入时能够灵活地进行状态转移。- 添加节点:通过
add_node方法,我们可以将不同的处理步骤(如query_or_respond、tools和generate)添加到状态图中。这些节点代表了系统在处理用户请求时的不同阶段。 - 设置入口点:
set_entry_point方法用于指定状态图的起始节点。在这里,我们将入口点设置为query_or_respond,这意味着系统将从处理用户查询开始。 - 添加条件边:
add_conditional_edges方法用于定义在特定条件下的状态转移。在本例中,我们根据是否调用工具的结果来决定是否继续到tools节点或结束流程。 - 添加边:通过
add_edge方法,我们可以定义节点之间的连接关系,确保在处理流程中能够顺利地从一个步骤转移到下一个步骤。 - 内存保存:
MemorySaver用于在状态图中保存当前的状态,以便在需要时能够恢复。这对于长时间运行的对话或多轮交互非常重要。 - 编译图形:最后,通过
compile方法,我们将状态图编译为可执行的形式,以便在后续的用户交互中使用。
10. 流式处理用户输入
最后,我们可以流式处理用户输入并生成响应。
1 | # 对于不需要额外检索步骤的消息,它会做出适当的回应 |
响应内容:
1 | ================================ Human Message ================================= |
11.总结
在本教程中,我们详细介绍了如何使用 langgraph 构建一个智能问答系统。我们从加载网页文档开始,经过文本分割、嵌入存储、工具创建、用户查询处理,最终生成响应。通过这种方式,您可以创建一个能够从网络文档中提取信息并选择是否使用提取信息来回答用户问题的 AI 助手。
12.完整代码
1 | import bs4 |