Python Flet教程(三):实现数据持久化
1.开篇陈述
在前两篇教程中,我们搭建了笔记应用的界面并实现了核心功能。但是目前所有笔记数据都存储在内存中,应用关闭后数据就会丢失。在这篇教程中,我们将:
- 使用SQLite实现数据持久化
- 添加数据库操作的错误处理
- 实现自动保存功能
- 优化数据读写性能
2.项目结构
1 | noter/ |
3.代码分步讲解
3.1 数据库结构(schema.sql)
1 | -- 创建笔记表 |
设计说明:
- 使用TEXT类型存储UUID,而不是INTEGER自增主键,原因是:
- 支持分布式系统的未来扩展
- 避免数据迁移时的主键冲突
- 与Note类的设计保持一致
- 添加updated_at索引的原因:
- 笔记列表默认按更新时间排序
- 频繁使用updated_at进行排序
- 索引可以显著提高查询性能
3.2 数据库操作类(database.py)
数据库初始化和连接管理
1 | import sqlite3 |
实现说明:
- 使用上下文管理器(with语句)自动管理连接
- 添加错误处理和日志记录
- 确保数据库目录存在
CRUD操作实现
1 | def save_note(self, note: Note) -> None: |
实现说明:
- 使用参数化查询防止SQL注入
- 统一的错误处理机制
- 使用事务确保数据一致性
- ISO格式处理时间戳
数据转换方法
1 | @staticmethod |
实现说明:
- 使用静态方法便于复用
- 处理时间格式转换
- 添加错误处理
3.3 更新Note类(note.py)
1 | from dataclasses import dataclass |
实现说明:
- 使用dataclass简化类定义
- 添加序列化和反序列化方法
- 统一的时间格式处理
- 完善的错误处理
3.4 更新主程序(main.py)
1 | import flet as ft |
实现说明:
- 数据库路径使用相对路径
- 添加用户友好的错误提示
- 统一的异常处理
- 实时保存机制
4.性能优化说明
- 数据库索引
- 为frequently查询的字段创建索引
- 使用DESC排序优化最新笔记查询
- 连接管理
- 使用连接池而不是频繁创建连接
- 自动关闭连接避免资源泄露
- 查询优化
- 使用参数化查询
- 避免SELECT *(实际使用中应该只选择需要的字段)
- 使用LIKE查询的优化索引
- 错误处理
- 统一的异常处理机制
- 用户友好的错误提示
- 详细的错误日志
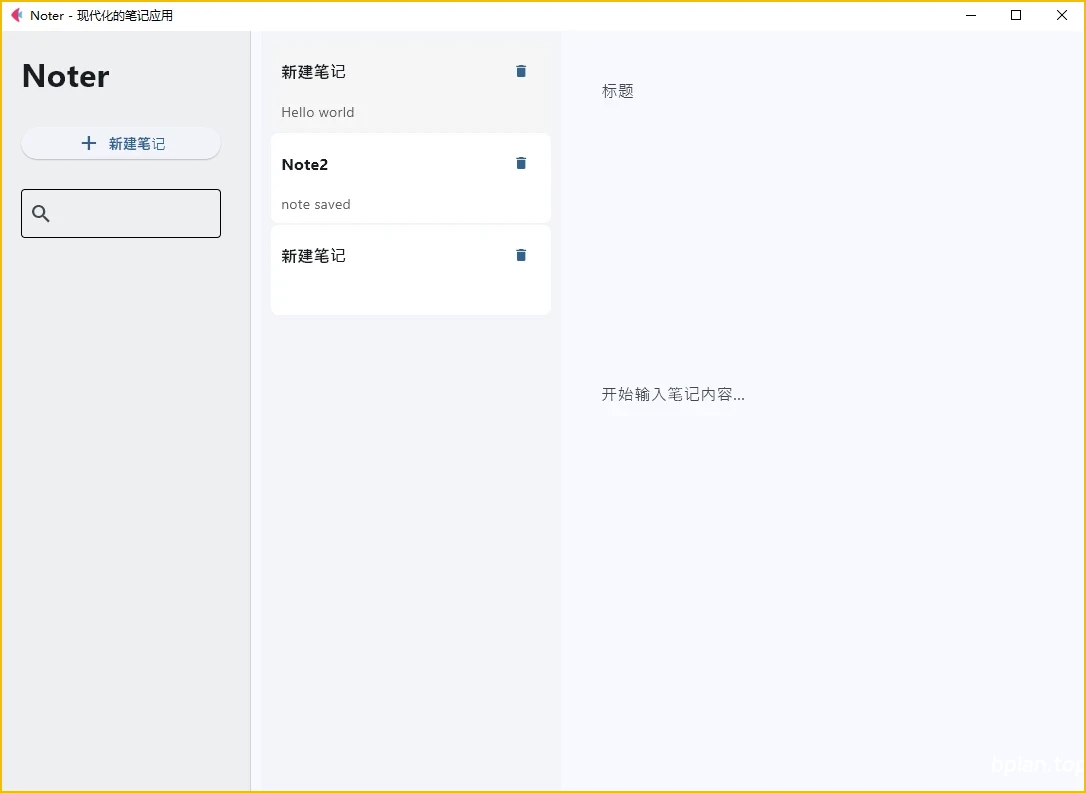
5.界面展示
如下是本篇完成后的笔记应用界面,初次打开时会加载已经保存的笔记内容:
6.本篇小结
在这一篇教程中,我们:
- 实现了数据持久化存储
- 优化了数据库操作性能
- 添加了错误处理机制
- 实现了更强大的搜索功能
- 确保了数据的可靠性和一致性